Pandora’s (black) box
AI agents, when let loose, are extremely powerful tools, potentially revolutionizing the way things are done in many industries. On the flipside, when left unchecked, they might be the biggest security nightmare in cyberspace since the invention of, well, cyberspace itself. How do we walk this tightrope? Is it even possible?
When researching this topic one quickly stumbles over arXiv:2509.08646, a research paper that is foundational for my thinking about secure agentic pipelines, and which might turn out to be foundational for the field as a whole. The paper is a comprehensive guide to the Plan-then-Execute (P-t-E) pattern. In this post, I describe a naive but functional OpenClaw implementation of P-t-E.
Why Having a Plan Is Reasonable
The basic premise of P-t-E is simple: instead of giving an AI agent full autonomy, you split it into parts.
You have one main agent, the planner, that you talk to directly. You tell it what you need, like talking to a human assistant, and it formulates a structured plan. These steps are then fed to another agent, the executor, which carries them out one at a time.
The advantages are described in detail in the paper linked above, which I highly recommend reading. I want to focus on two features here: Human-in-the-Loop (HITL, having a human sign off on AI actions at critical points) and the principle of least privilege (giving each agent exactly the tools it needs, and nothing more).
Why letting the AI agent do everything is a terrible idea
Many AI pipeline setups keep the LLM in the execution loop the entire time. The agent reasons, decides, and acts in one continuous flow. If something goes wrong, or if the agent was manipulated via prompt injection somewhere along the way, you find out after the fact. Or, if the attacker is sophisticated, you find out never.
It should be pretty obvious that this is unacceptable for any kind of operation. Every serious business has checks and balances at critical points and intersections. Your AI pipeline needs those as well.
The good news is that introducing mechanisms for making a pipeline secure is very doable. While an agent with internet access, memory, and the ability to send emails can rather easily be convinced to send a motivated attacker all your sensitive data, the dangers are mitigated significantly if you deprive the agent of one of those capabilities. The combination of private data access, untrusted content exposure, and the ability to communicate externally is called the “Lethal Trifecta”, a term coined by Simon Willison, which I’ve written about before here. Any agentic pipeline that combines these three capabilities without appropriate security measures is a ticking time bomb.
I developed a tool called BreakLeg that helps visualize the dangers of the Lethal Trifecta. You can check it out here.
The Approach: Intent as a Data Contract
I initially had only one agent with root access on one of my servers. Since the dangers of this became apparent rather quickly, I sandboxed it. This takes away its ability to communicate with most of the outside world. Exceptions being of course the LLM provider, and the channel that I use to communicate with the agent. This channel in my case is Telegram; a fact that has horrible security implications by itself (a topic for another time).
Since an agent with no internet access is pretty limited in its use I attempted to design a system that lets me dispatch research tasks to other agents which can access the internet but don’t have access to the private data.
The core idea is simple and has significant consequences: the LLM’s output should be a structured document, not an instruction to execute immediately.
Instead of “AI decides and acts,” the flow becomes:
- You tell the main agent what you need
- The agent writes a structured intent document and puts it in a queue
- A human reviews the intent and approves or rejects it
- Only after approval does the executor consume the intent and act on it
- Any subsequent LLM calls happen within tightly constrained boundaries
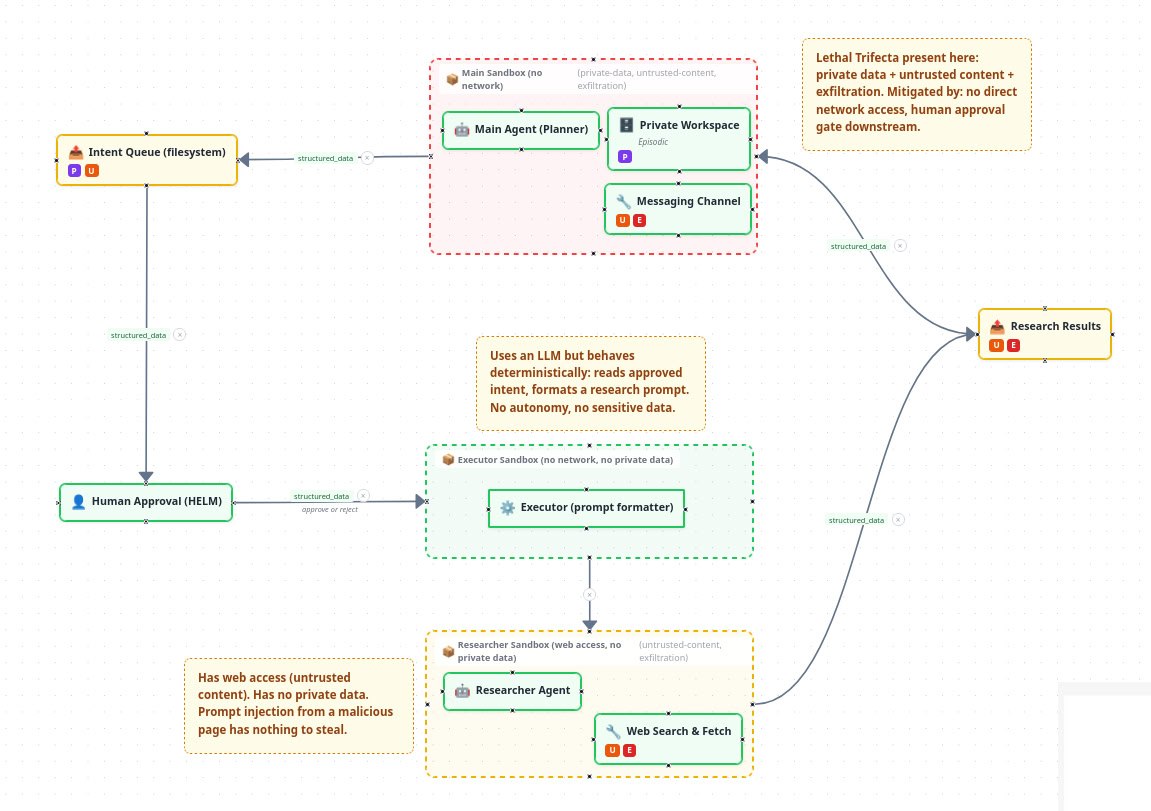
This is considerably more safe than having an AI just do it all: The main agent’s autonomy ends at the intent document. After that point, two more LLMs are involved, but each operates in a sandbox with a clear objective and only those tools available that it needs to finish that objective:
The executor formats the approved intent into a research prompt. It has no network access and no private data. It cannot do anything harmful with the intent it receives.
The researcher runs the actual query with web access. It has no access to private data, so even if it is manipulated via prompt injection from a malicious web page, there is nothing sensitive for it to leak.
This is the Lethal Trifecta split across agents. No single LLM has all three dangerous capabilities at once: private data access, untrusted content exposure, and exfiltration ability. Which in itself is not enough to make it secure. If you just pipe the data between the agents without approval you are basically back to the “one agent does it all”. The human approval step between the planner and the executor breaks the flow of potentially sensitive data, thus breaking the Lethal Trifecta.
This approach has several further properties worth noting:
The approval is meaningful. You are not approving a vague prompt. You are approving a data contract: a JSON object that specifies exactly what will happen. The AI cannot change its mind mid-execution.
Everything is auditable. The intent document, the approval decision, and the result are all persisted. You have a complete record.
The blast radius is limited. If the main agent was manipulated via prompt injection, the worst it can do is write a bad intent document. The human in the loop catches it before it executes.
It is cheaper. The executor and researcher can run on lighter, cheaper models. Only the planner needs the expensive frontier model for reasoning.
A reasonable question at this point: why have both an executor and a researcher? Could the researcher not just receive the approved intent and format its own prompt?
For simple research tasks, yes, it could. The executor is a deliberate design choice, not a necessity. It keeps the prompt-formatting step in a context that is clean and isolated from web content. It also acts as a dispatch layer: as the pipeline grows beyond research into scheduling, file operations, or API calls, the executor decides which downstream agent handles each intent type. The layering is a design decision that pays off as pipelines become more complex. For a minimal first implementation, collapsing executor and researcher into one would work fine.
What I Built
Explore this pipeline interactively in BreakLeg
I built this on top of OpenClaw, using a file-based pipeline:
- The main agent writes a JSON intent file to a queue directory
- A small web app I built called HELM shows pending intents on my phone via Tailscale
- I review the intent and tap Approve or Reject
- On approval, HELM copies the intent to the executor’s workspace and calls the executor agent
- The executor formats a research prompt from the intent and calls the researcher agent
- The researcher runs in an isolated sandbox with web access but no private data
- Results are timestamped and copied back to the main agent’s inbox
The file system is the coordination layer. No message queues, no workflow engines, no cloud services. Files appear in directories, scripts copy them, systemd watches for triggers. It is boring on purpose. Boring is auditable. Boring survives reboots.
Some stuff for nerds
For those interested in the implementation, here are some details.
The intent JSON looks like this:
{
"type": "research",
"topic": "Safe agentic pipeline patterns",
"scope": "2024-2026",
"questions": ["What patterns exist?", "Which tools are similar to what we've built?"],
"context": "We built a file-based HITL pipeline...",
"createdAt": "2026-03-26T16:31:00Z",
"createdBy": "main-agent"
}The type field drives dispatch. When HELM approves a research intent, it calls the research pipeline. Adding a new action type (reminder, cron job, config change) means adding one handler. The architecture is open by design.
The security model is equally explicit:
- HELM binds to the Tailscale IP only, never the public internet
- The executor has no network access and no private data other than the approved research intent
- The researcher has network access but no private data
- The main agent has private data but no network access
This is the Lethal Trifecta split across agents. No single agent has all three legs. The human gate between the main agent and the executor is where the trifecta is broken in the data flow.
One documented parallel to this architecture is Temporal’s durable workflow model, which achieves similar guarantees through a workflow engine. The file-based queue approach is simpler and more auditable for a single-user personal setup, but the principle is the same: LLM calls are side effects, orchestration is deterministic.
Is This Worth the Effort?
For a personal setup, probably not if you just want to run a few automations. But if you are building anything that:
- Touches real data
- Sends anything to the outside world
- Involves non-technical users approving AI actions
- Has regulatory or compliance dimensions
…then the pattern is worth understanding. The EU AI Act’s Article 50 (interaction disclosure requirements, enforceable August 2026) and EDPS guidance explicitly warn against “comprehension theatre” where users approve things they do not understand. An intent document reviewed at a human gate is a meaningful step toward compliance, not just security.
The full pipeline, the HELM web app, and the BreakLeg security analysis tool are being prepared for open source release. Follow along at amathia.org.
The research paper referenced in this post: arXiv:2509.08646 “Architecting Resilient LLM Agents: A Guide to Secure Plan-then-Execute Implementations” (September 2025)